
|
|
Here is a ``smart'' program for indexing and retrieval of documents.
By Hans Paijmans
Although my colleagues here at Tilburg University may think the time I spend fiddling with Linux on a PC could be put to better use, they are wrong. The ``fiddling with Linux'' I do at home; at work I do only the minimum necessary to keep Linux fed and happy. As most readers of this journal know, this involves making the occasional backup and not much else.
When I sit in front of my PC, I work (well, mostly). Linux makes it possible to do my work with a minimum of fuss, and a big part of the credit for this goes to Jacques Gelinas, the man who wrote UMSDOS: a layer between the Unix operating system and the vanilla MS-DOS file allocation table. This program makes it possible to access the DOS partition of my hard disk from either operating system. This is good news, since I am totally dependent on two programs: SMART, an indexing and retrieval system, and SPSS for Windows, which twiddles the data I obtain from SMART. SMART runs only under Unix (and not all Unices, for that matter) and SPSS4Windows, obviously, runs under MS Windows. Whatever the virtues of this operating system may be, you emphatically do not want to use it in any kind of experimental environment.
I suppose Statistical Package for the Social Sciences (SPSS) will be familiar to most Linux users. If not--SPSS is a statistical package not only for the ``social sciences'', but also for anyone who needs statistical analysis of his data.
SMART is an indexing and retrieval program for text. It not only indexes the words, it also adds weights to them. It allows the user to compare the indexed documents in the Vector Space Model and compute the distances between documents or between documents and queries. To understand why this is special, we must delve a bit into the typical problems of information retrieval, i.e., the storage of books, articles, etc., and their retrieval based on content.
At the end of the 60s, automatic indexing of texts became a viable option, and many people thought the problems of information retrieval were solved. Programs like STAIRS (IBM, 1972) enabled the users to file and rapidly retrieve documents using any word in the text and boolean operators (AND, OR, NOT) with those words--who could ask for more? Then in 1985, a famous article was published by two researchers in the field. Footnote 1. In this article, they reported on the performance of STAIRS in real life, and they showed that the efficiency of STAIRS and similar systems was, in fact, much lower than assumed. Even experienced users could not obtain a recall of more than 20-40% of the relevant documents in a database of 100,000 documents, and worse, they were not aware of this fact.
The problem with all retrieval systems of this type is that human language is so fuzzy. There may be as many as a dozen different terms and words pointing to one and the same object, and one word may have widely different meanings. In information retrieval, this can lead to one of two situations. One, you obtain a high precision where almost all the retrieved documents are relevant, but an unknown number of other relevant documents are not included. Or two, you get a high recall that includes a lot of irrelevant documents in the result. When the proportion of irrelevant documents is high in a retrieved set of documents, the user will most likely stop looking before he or she has found all the relevant documents. At this point, his ``futility-point'' has been reached. In such a case the net result is equivalent to those relevant records not being retrieved. Therefore, the concept of ranking, i.e., the ordering of retrieved documents based on relevance, is very important in information retrieval.
Modern (and not so modern) research has offered a number of possible solutions to this dilemma, among them the concept of weighted keywords. This means that every keyword-document combination has a weight attached that is (one hopes) an indication of the relevance of that particular keyword for that particular document. SMART does just that: it creates indices for a database of documents and attaches weights to them. The method may be expressed intuitively as ``the more a word occurs in fewer documents, the higher the weight.'' If the word ``dog'' occurs twenty times in a given document but in no other documents, you may be relatively certain that this document is about dogs. Information retrieval addicts like me talk about the tf.idf weight.
SMART offers several calculation options (I generally prefer the atc-variation, because it adjusts for the length of the individual documents.) It calculates the tf.idf in three steps. The first step creates the value
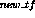
for the term-frequency (tf) as:

where
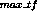
is the term with the highest frequency in the document. This adjusts for the document length and the number of terms. Then the weight


where N is as before the number of documents and F is the document frequency of term t (the number of documents in which term t occurs). Finally the cosine normalization is applied by:

where T is the number of terms in the document vector. Now we have a number between zero and one that probably correlates with the importance of the word as a keyword for that document. For a detailed discussion of these and similar techniques see Salton and McGill. Footnote 2. You will love it.
When SMART has constructed the index in one of the various ways available, it can also retrieve the documents for you. This is done according to something called the ``Vector Space Model''. This model is best explained using a three-dimensional example of a vector-space; you can add another few thousand dimensions in your own imagination.
Imagine you want to index your documents according to three keywords--``cat'', ``dog'' and ``horse''--that may or may not occur in your documents. So you draw three axes to get a normal three-dimensional coordinate system. One dimension can be used to indicate the ``cat-ness'' of every document, the other its ``dog-ness'' and the third the ``horse-ness''. To make things easy we use only binary values 0 and 1, although SMART can cope with floats (e.g., the ``weights'' mentioned before). So if a document is about cats, it scores a 1 on the corresponding axis, otherwise it scores 0. Any document may now be drawn in that space according to the occurrence of one or more of the keywords, and so we have a relatively easy way to compute the difference between documents. Moreover, a query consisting of one or more of the keywords can be drawn in the same space, and the documents can be ranked according to the distance to that query. Of course a typical document database has thousands of keywords and, accordingly, thousands of dimensions, but the arithmetic involved in multi-dimensional distances does not matter much to modern computers.
So SMART accepts queries, ranks the documents according to the ``nearness'' to that query and returns them to you in that order. This ability makes it one of the best retrieval systems ever written, even though it lacks the bells and whistles of its more expensive counterparts. Although it is not really optimized for speed, it typically runs 10-30 times faster than the fastest indexing program for MS Windows that I have tried.
I do not use SMART for bread-and-butter retrieval, but for the weights it computes and the indices it creates. At this point I usually want to do some other manipulations of the data. I offer my thanks to the developers of Unix in general and to Linux in particular for creating a whole string of ever more complicated and sophisticated shell scripts, the standard Unix tools and a few of ``My Very Own'' utilities that suffice to process the SMART output to a file that is ready for import into SPSS.
Now I have to quit Linux and boot MS-DOS, start MS Windows and finally enter SPSS to do the statistics and create some graphs. I am a newcomer to Unix (indeed it was the fact that Linux offered a way to use SMART that pulled me over the line two years ago). While MS Windows is not my favorite operating system, SPSS gets the job done. When the output is written to disk, I immediately escape back to Linux to write the final article, report, or whatever with LaTeX.
On this point I have two messages--one bad. The good news is that SMART is obtainable by anonymous ftp from Cornell University and can be used free for scientific and experimental purposes. Better yet, it compiles under Linux without much tweaking and twiddling. There is also a fairly active mailing list for people who use SMART (smart-people@cs.cornell.edu).
The bad news: the manual--what manual? SMART is not for the faint of heart; after unpacking and compilation, you'll find some extremely obscure notes and examples, and that is all. Nevertheless, if you have more than just a few megabytes of text to manage and the stamina to learn SMART, it certainly is the best solution for your information retrieval needs. I do wish someone would write a comprehensive manual. In the meantime, you may be helped by my ``tutorial for newbies'' found at http://pi0959.kub.nl:2080/Paai/Onderw/Smart/hands.html.
Hans ``Paai'' Paijmans is a University lecturer and researcher at Tilburg University and a regular contributor to several Dutch journals. Together with E. Maryniak, he wrote the first Dutch book on Linux--already two years ago. My, doesn't the time fly? His home page is at http://pi0959.kub.nl:2080/paai.html, and he can be reached via e-mail at paai@kub.nl.
This article was published previously in Issue 13 of the Linux Gazette.